
MNIST
MNISTで始める画像分類モデル
最もシンプルなニューラルネット を作ってみましょう!
ここでは手書き数字データセットのMNISTというものを使います。これには次のような28×28の画像が含まれています。

ここでの課題は、0 ~ 9 までの10個の数字を識別すニューラルネット を作ることです。
まずは使うライブラリを読み込みましょう。
10行目から14行目でMNISTデータセットをダウンロードしニューラルネット にデータを与えられるようにしています。
では早速、3層のネットワークを定義しましょう。
Networkの定義
ここでいくつか新しい用語が出てきたので解説します。
nn.Linear()
一般的に全結合層と呼ばれる層の事です。数式で表すと、
y=xW+b
と書く事が出来ます。xは入力、Wは重み、bはバイアスです。
nn.ReLU()
ReLU関数は以下のように示される活性化関数です。
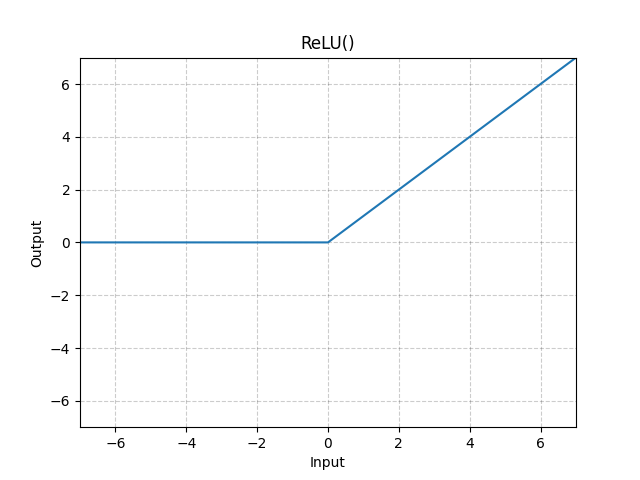
ニューラルネットは基本的に層と活性化関数交互に重ねて設計されます。
学習
ネットワークの定義が完了したので早速訓練をしましょう!
fit()関数について解説していきます。まず一行目の
は、GPUが利用可能な場合 "cuda" が選択されCPUのみの場合 "cpu" が選択されます。この結果は、
や
で利用されます。
では、 for の中身を見ていきましょう。
は今回用いるネットワークが全結合層で構成されている為、入力は [samples, features] の2次元配である必要がある為、元々の形状 [samples, channels, features] から変更しています。
評価
評価では学習したネットワークの性能を評価してみましょう。
Last updated